Disaster Recovery (DR)
The Only Guide You Will Need
From the definition of Disaster Recovery, right down to DR planning and technologies, we cover everything in this ultimate Disaster Recovery guide.
20 min read
What do we mean by ‘Disaster Recovery’?
The ability to recover from a disaster is as important to your business as daily running operations, even more so with the number of growing threats that can impact your bottom line.

Reports of ransomware attacks are becoming more common every day. Add to that the effects of climate change and disasters, both man-made and natural, that underscore your need to plan how to continue business operations if a disaster should strike.
Disaster Recovery is a crucial component of this planning. This guide will explain what it is, why it’s important to your company, how to plan a Disaster Recovery solution and how to integrate it into your business.
Disaster recovery applies to all types of business, and in all sectors, it’s a matter of investment. Given that your data and systems are crucial to the success of your business and the ability to earn revenue, you will have a significantly higher investment and spend more time planning for disaster recovery than a business like a local cafe. That being said, even your local cafe needs to have a plan in place in case of a fire, flood, power outage, and other adverse events that can affect daily business operations.
What’s Trending: The State of IT Disaster Recovery
The State of Data Protection and Disaster Recovery Readiness: 2021
The 2 Categories Of Disasters
Disaster can take many forms but fall into the category of either natural and/or man-made. A disaster recovery plan should have scenarios that deal with each type of potential disaster.
Examples of natural disasters are earthquakes, hurricanes/typhoons, tornadoes, floods, wildfires, or tsunamis. These disasters can cause severe physical destruction and can also disrupt power grids and communication networks over large areas. Naturals disasters can also have cascading effects producing additional disasters such as an earthquake causing a tsunami or a hurricane causing severe flooding.
Man-made disasters are also a significant source of risk. Man-made disasters can be intentional in the form of a malware attack (such as ransomware), insider theft, intentional sabotage, a terrorist bombing, a hack to disrupt a power grid or communication system. Man-made disasters can also be unintentional in the form of an application misconfiguration that takes down a cloud computing platform, an accidental explosion in an industrial facility, or an infrastructure failure in a power grid or communication system.
In either disaster category, utilizing a tiered system for response is a critical component to ensure that you respond appropriately. Establishing the matrix of critical business applications and processes and their corresponding Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) will ensure that your disaster recovery response rapidly returns your business to productivity in the shortest amount of time possible while minimizing the potential for data loss.
RTO & RPO: How to Measure Disaster Recovery
The recovery time objective (RTO) and the recovery point objective (RPO) are two important metrics in disaster recovery. Both are measured in time; RTO is the time it takes to bring systems back online with recovered data after a disaster event and RPO is the closest point in time before a disaster occurs to which data can be recovered.
Your desired RPO is determined by asking how much data your business can tolerate losing in an incident and still be able to remain viable with minimal impact. Based on business criticality, you may have a different RPO for each application or system. The RPO you can achieve will depend on your recovery plans and your recovery solution or solutions. Supporting multiple RPOs across different systems will require either multiple solutions or a flexible solution that can provide multiple RPO options.
RTO and RPO: Differences and Considerations
RTOs and RPOs: Lowering the Cost of Recovery
Your desired RTO is measured by how long you can be without your data and systems or how long it will take for business operations to return to normal after an outage or interruption. For many businesses, the cost of one hour of downtime can reach up to six figures. Downtime affects productivity, the ability to do commerce, and damages customer confidence, customer satisfaction, and brand reputation and loyalty. Like RPO, the RTO that can be achieved is determined by your recovery plans and recovery solution. The choice of recovery solution can determine whether your RTO is measured in minutes, hours, or even days...
Ransomware Resilience in Disaster Recovery
One of the most straightforward applications of Disaster Recovery comes when combating the expanding menace of ransomware.

Ransomware attacks are when hackers use malicious software to lock and encrypt files on your computer. These attacks are successful because most businesses do not have a proper DR plan that has been fully fleshed out and practiced. Without a DR plan in place, companies are at the mercy of the criminals. After the attack, they find themselves having to pay the ransom to unlock the system or application, or they’re paying to prevent the exposure of exfiltrated customer data.
To combat ransomware, a proper DR plan that has been tested and familiar to all relevant technology players is the most crucial component. Proper DR planning gives your business the leverage and assurance to respond to ransomware threats.
Beat Ransomware with Recoverware
Cyber-Resilience: Carpe Data and Fight Back Against Ransomware
Disaster Recovery Testing – It May Just Save Your Business
CDP-based DR Solution Helps Tencate to Recover from Ransomware
As a reference, in 2019, the city of Baltimore was attacked by hackers and had its systems subjected to ransomware attacks. Ten thousand servers and workstations were encrypted, real estate closings crawled to a stop, water bills could not be generated, and a number of other systems were unavailable, resulting in a financial impact to end-users. It took weeks to correct because there was not a full DR plan in place. The eventual cost of the incident was estimated at over 18.2 million dollars¹.
In contrast, Tencate, a multinational textiles company based in the Netherlands, experienced ransomware attacks twice.
The first time, one of its manufacturing facilities was hit with CryptoLocker, which infected all its file servers. At that time Tencate was only able to restore from disk and as result experienced 12 hours of data loss, and was not able to recover for two weeks.
The second time, a more advanced form of CryptoLocker hit a manufacturing faciity, but this time Tencate had a distaster recovery solution based on continuous data protection (CDP). The result: 10 seconds of data loss and full recovery under 10 minutes.
Disaster Recovery + Business Continuity: What’s the Relationship?
Disaster recovery and business continuity have a direct relationship: Disaster recovery is a key component of a successful business continuity management program

In other words, the business continuity component deals with the overall program and processes that would bring a business back into operation and allow the organization to begin earning revenue again. Disaster recovery is the playbook that is followed in order to bring the individual components back online after a crisis happens.
Essentials: Business Continuity Guide
Business Continuity Plan (BCP) vs. Disaster Recovery Plan (DRP): What Are the Key Differences?
Key components of a Business Continuity Plan
Disaster recovery solutions often allow for non-disruptive patch testing without concerning the impact of a misconfiguration. Replicated data at disaster recovery sites can be used to create isolated test environments for patch testing which does not impact production. When rolling a patch into production, if the patch causes an issue, the disaster recovery solution can roll back the production environment to the last RPO.
Similarly when using a disaster recovery technology to perform workload migrations, if there is an issue with the migration process, the server workload can be rolled back to production quickly.
Each of these scenarios will have an entry in the business continuity plan and supporting documentation and processes to allow users to execute on-demand.
In disaster recovery and business continuity, RTO and RPO are two critical metrics that must be given individual consideration in a proper DR solution.
Backup is most definitely NOT Disaster Recovery
Although the terms are often used interchangeably, it’s important to understand the distinction between backup and disaster recovery.

One without the other will result in a failure of both, but they have critical differences.
Backup is a duplication of a data set at a specific point in time. This data backup can be used to restore the data to its original state at the time of the backup. This helps to ensure the integrity of the data and the information governance of your business. A solid backup system is a crucial component of a properly structured disaster recovery plan.
In case of a major disruption to your infrastructure, a backup solution won’t allow you to restore your operations, since your applications and data wouldn’t have any infrastructure to run on.
Disaster Recovery vs. Backup: Are the Lines Blurring?
Disaster recovery focuses on the duplication of the existing infrastructure with the end goal of resuming normal business operations as quickly as possible. This process is employed in the event of natural or man-made disasters, such as floods; earthquakes; a terrorist incident; or even faulty configuration or patching.
A disaster recovery plan is the documented process and training for recovering business-critical services, applications, and systems from an unplanned event. DR includes the people and processes and factoring in the recovery time objective (RTO), and the recovery point objective (RPO).
A backup solution can sometimes meet RPO and RTO requirements for isolated events, but for true disaster scenarios that affect entire sites, their recovery capabilities are not adequate for recovering within minutes or even hours. In the context of recovering your business to total production, backups are better for long-term data retention rather than 24/7 recovery services. Backups don’t address maximum tolerable downtime in any meaningful way.
The Costs of Downtime and Recovery, Should A Disaster Strike
Take a moment and imagine your business runs around the clock, perhaps an e-commerce platform, and you are making money every minute.

Unexpected or unplanned downtime and the following recovery period will cost your business money for every second that it’s offline. Or perhaps you work in an organization that bids on jobs, like construction or professional services. If your systems go offline right at the close of bid, it could cost you the contract.
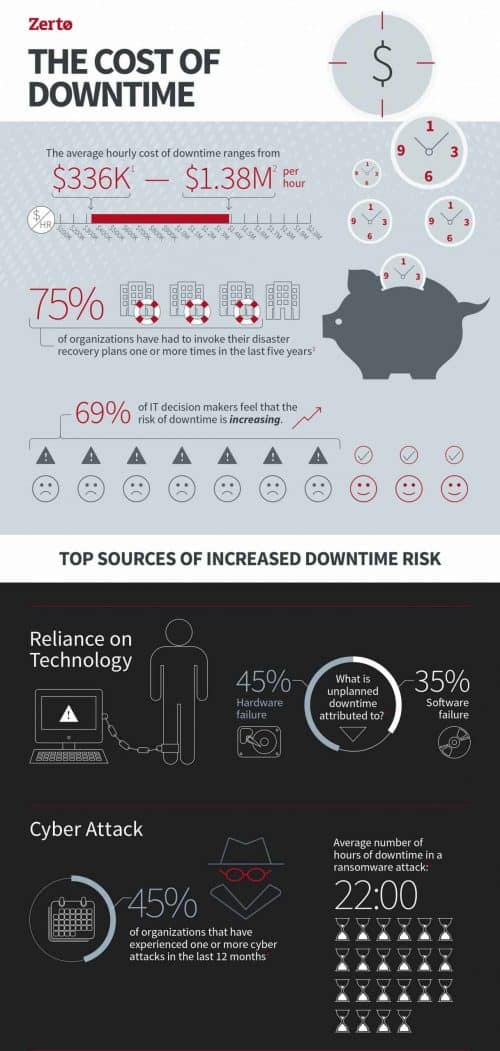
Cloud Alone Is Not Enough. You Still Need Disaster Recovery
Reducing the Costs of Downtime for Federal Agencies
Prolonged outages may cost your organization lost business, impaired productivity and irreparable reputation damage on.
Unplanned downtime and data loss can sometimes strike when you least expect and even when you are most vulnerable to high downtime costs, but with a proper DR plan in place, you can set the mitigation point to what your business is comfortable with in terms of recovery times and recovery points. Near-synchronous replication and continuous data protection can offer assurances of minimal operational impact in the event of an outage and can translate into cost avoidance for extended periods of operational impacting events.
To quantify the potential costs of downtime and recovery, you need to perform a critical asset analysis and then a business impact analysis to tier your systems and applications regarding their business importance. After tiering them, you would then assign resources to determine the acceptable risk appetite for unplanned events. That will allow you to quantify downtime costs and allocate the proper resources to ensure the recovery and downtime pieces fall within the business risk appetite.
Disaster Recovery: How To Plan And Strategize
In developing your DR strategy, some common steps that should be followed are:

- Capture all the relevant assets and components of the plan. A full asset audit of data and IT inventory needs to be performed to identify the assets in the business. This can be a one to two-day engagement using a discovery tool.
- After you know all of the assets, you should work with the business area owners to determine the impact of each application or system to build a risk inventory. The risk inventory involves running a risk assessment to determine the value of the service to the business. You will need to tier the assets in terms of workload prioritization and their value to the overall business operations.
- After the risk inventory, you need to perform a business impact analysis on each critical system. This often takes the most time because it’s on a per-application/system basis but it ensures maximum return on the investment.
- With the business impact analysis in hand, you can begin to build acceptable RPO and RTO targets and then be able to determine the budget requirements of fulfilling the recovery targets.
- Once you have RPO and RTO targets, you make the investments to support your DR needs, you can establish your DR plan and all its related runbooks based on the type of various types of disruptions.
- Finally, you need a team to execute the plan, often called the Incident Response team. Clearly defining roles, responsibilities, and authority will ensure that all of the work put into DR planning will be worth it.
- You need to revisit and test the DR plan on at least an annual basis, if not semi-annual, or ideally even more frequently if your solution allows for this.
How Are Organizations Protecting Their Data in the Cloud
As part of your strategy, consider how the cloud can be integrated into your solution and if it offers benefits in cost savings or recovery efficiency in your DR solution.
Disaster Recovery Planning
From Chaos to Calm: Steps to build a Rock-Solid DR Runbook
Total Cost of Ownership
Once you have performed a business impact analysis and developed a disaster recovery strategy, you can calculate the total cost of ownership (TCO) or your DR plan and solution.
You get the TCO by adding the upfront costs of the solution, including the implementation and configuration time, recurring monthly costs if it is a hosted solution, fees associated with storage and monitoring, and the administrative costs for maintenance and testing.
Example of a TCO Model
Calculating TCO of Storage Based Replication
RPO and RTO requirements may impact the cost of the solution. A solution that provides faster recovery within minutes for an entire site failure or that minimizes data loss to only seconds may increase the cost of the solution compared to solutions with slower recovery times or more data loss. DR solutions may vary significantly in architecture and cost despite offering a similar RTO and RPO.
A Disaster Recovery Checklist
Below is a checklist of things to consider when planning and strategizing for your disaster recovery:

- Perform IT application and system inventory (2-3 days with automation)
- Perform a risk assessment to estimate the impact of downtime due to a disaster
- Perform a business impact analysis on each process/system/application (1 day per application should suffice)
- Create the RPO and RTO for each component and document it. This will involve executive approval so plan around the current meeting timeframes.
- Document and review the current DR plan if it exists and identify gaps
- Integrate 3rd party solutions where appropriate
- Implement the response team
- Test the DR plan and document results
- Plan for annual review
How To Choose your DR Solution:
Part 1: Replication Technologies
In support of the complex process of disaster recovery, there are a number of replication technologies to consider.

Replication vs Backup: What are the differences?
Synchronous, A-Synchronous and Near-Synchronous Replication Technologies
Each has its own advantages; however, some may be more suited to your business goals based on your environment along with your RPO and RTO requirements.One technology decision that may determine what is best for your goals is the replication technology used in the solution. There are many types of replication technologies to choose from each with its own advantages and limits.
Array-based Replication:
Array-based replication products are provided by the storage vendors and deployed as modules inside the storage array. They are single-vendor solutions, compatible only with the specific storage solution already in use.
Appliance-based Replication:
Appliance-based replication solutions are similar to array-based solutions. They are hardware-based and specific to a single platform. The main difference is that the replication code runs on an external, physical appliance instead of inside the storage arrays themselves. This gives it an advantage over array-based solutions because it is more flexible and does not consume array resources. However, and as for array-based replication solutions, they are not well suited for virtualized environments as they too replicate physical rather than
virtual entities.
Host-based Replication:
Also called, guest/OS-based replication, this type of solutions comprises software components that must be installed on each individual physical and virtual server. Although much more portable than array-based solutions, having to install a module on every single serve limits scalability and makes it impossible to implement and manage in high-scale enterprise environments.Another significant drawback is that there are no consistency groups, as each VM is protected individually. This is counter intuitive to applications that typically span across multiple VMs.
Hypervisor-based Replication:
If your environment utilizes virtualization, then hypervisor-based replication of your virtual machines and network shares is a consideration. Utilizing snapshots and automated system replications offers a full recovery infrastructure that can offer the highest protection for your businesses.
On the other hand, software-based replication tends to be more cost-effective because of the way the data is replicated rather than doing on-premise. Exact sector by sector backups, software-based replication records an original data set to cloud-based, hosted servers and then records the incremental difference in the backup.
Software-based replication is machine agnostic in terms of requiring supporting infrastructure and can offer greater functionality. The level of investment to achieve real-time replication may be higher, depending on the need and the vendor.
Part 2: Recovery
The recovery options that a solution provides are also very important in picking the right solution.
Beyond Legacy Backup and DR: It’s All about the Recovery
Recovering Complete Applications in a Consistent Manner
Replication can ensure data integrity, but recovery determines when you will have access to the data again after a disaster occurs. Automation and orchestration are two critical components of an effective recovery solution because they remove manual steps that may delay the recovery time. After initial configuration, the automation and orchestration pieces will ensure that your recovery is executed within the desired SLA to the proper RTO and RPO.
Depending on your application, you may need a solution that provides very granular recovery options. Most solutions provide file-level restore capability, as well as the whole disk. In the event that a single file is deleted, a granular solution can recover it with ease. The trade-off is the administrative overhead of setup and maintenance, so factor that into the overall cost of ownership. The ideal would be a self-service-based recovery portal for single one-off file issues.
DR Implementation:
On-premises, in the cloud or as a service?
There are multiple ways to deliver disaster recovery. There is no right or wrong option. It all depends on your organization's model, legacy technology, available resources and risk management strategy.

Let's have a look at the different basic deployment models available while keeping in mind that an organization may end up implementing a DR solution combining multiple models.
DR on-premises
One deployment method for disaster recovery is to host the infrastructure on premises in a secondary site owned and managed by the organization.
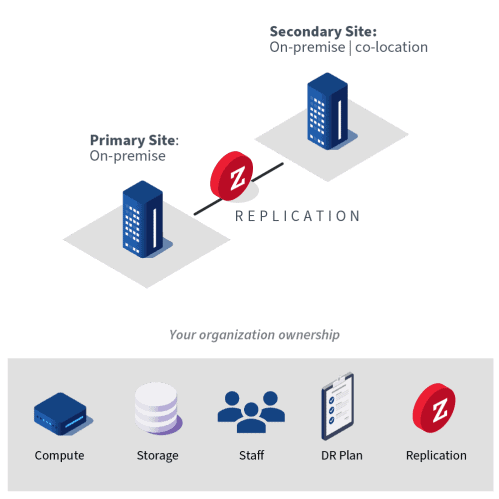
How it works
In this scenario your hardware, backups, and personnel are all “on site” where your office is and can directly intervene during DR situations. The largest benefit to an on-premises DR is having total control of the DR infrastructure so that you can choose your own hardware and software solutions, and not be reliant on a third party. This can allow you to develop all of your own processes for DR planning to achieve your RPO and RTO requirements. Having full control allows you to control costs, especially if you already have a suitable DR site within your organization so that you do not need to make a large investment in developing a new DR site.
Having total control of your on-premises DR site does require that you have the in-house expertise to properly set up and maintain the infrastructure and solution. You are also responsible for managing relevant privacy and data regulations. If this expertise exists in your organization, there can be significant savings over contracting a third party to implement. The downside is that if you lose your in-house expertise, on-prem solution may become very difficult and costly to maintain.
One more issue to consider for your on-premises DR site is location and resiliency. An on-premises location may not be as resilient as a public cloud platform when it comes to natural disasters. A suitable location would be geographically distant from the primary site (in another city or state) and not in a area prone to disasters such as hurricanes or floods.
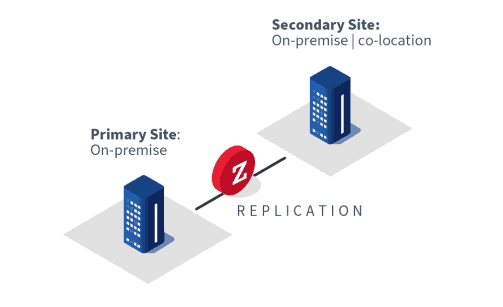
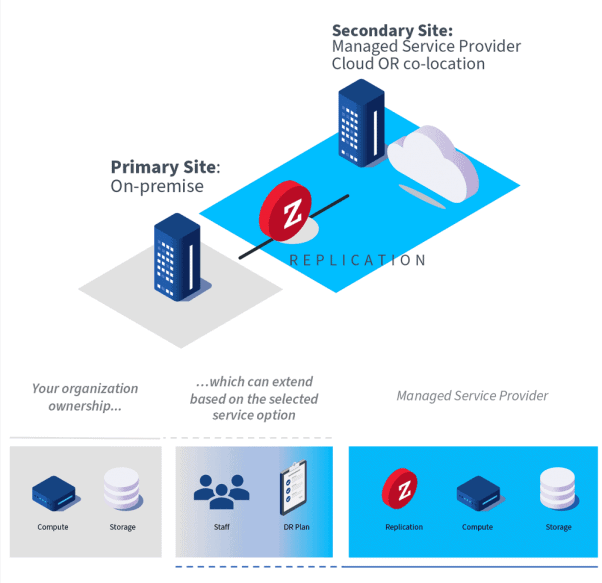
DR to the cloud
DR to the cloud refers to the outsourcing of the DR infrastructure to a cloud provider.
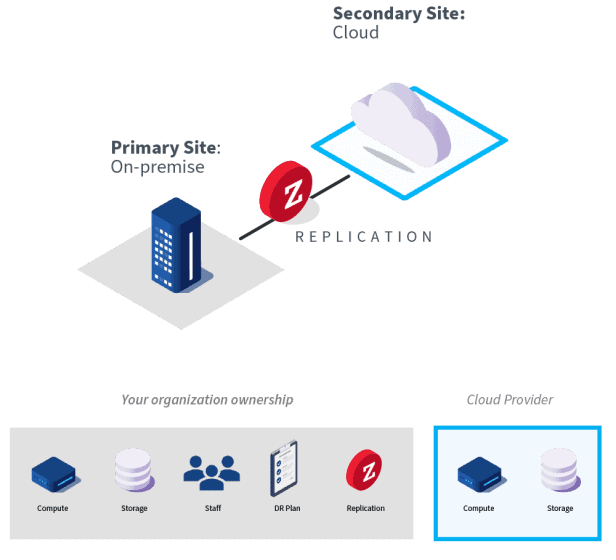
How it works
The advantages of a DR to the cloud solution are primarily in having a ready-made infrastructure as a DR site available with the cloud. From a financial perspective, the initial investment in the infrastructure, systems, and maintenance staff is avoided. You can plan your budget around predictable costs and OPEX (operational expenditures) rather than having to make a CAPEX (capital expenditure in a DR site.
DR to the cloud is particularly helpful when your organization does not already have a suitable DR site on-premises. Clouds are often spread across multiple datacenters for added resiliency and allow flexibility for scale out or scale up without having to physically add infrastructure as you would in an on-premises site.
The cost of cloud differs significantly from on-premises computing and understanding these costs can be key to making DR to the cloud successful for your organization. Cloud costs include data ingress and egress fees (costs for moving data in and out of the cloud), as well as storage and computing usage costs within the cloud. Organizations that do not fully understand these costs run the risk of overrunning their budgets. Having an SLA with a cloud DR provider ensures that your RTO and RPO will always be maintained. The compliance requirements relating to data and privacy fall into the responsibility of the cloud provider.
DR to the cloud can be in the form of infrastructure as a service (IaaS) where you use the cloud infrastructure but otherwise manage the rest of the DR solution yourself, or it can be in the form of disaster recovery as a service (DRaaS) where a third party is managing the DR solution for you.
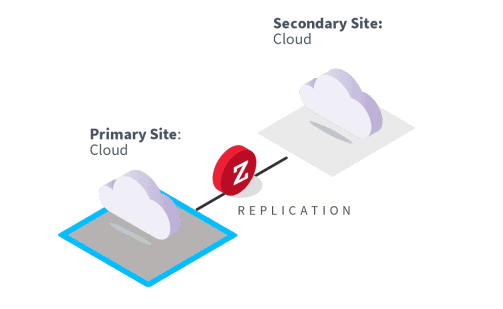
In-Cloud DR
In-Cloud DR refers to the outsourcing of both the primary and DR infrastructure to one or more cloud providers.
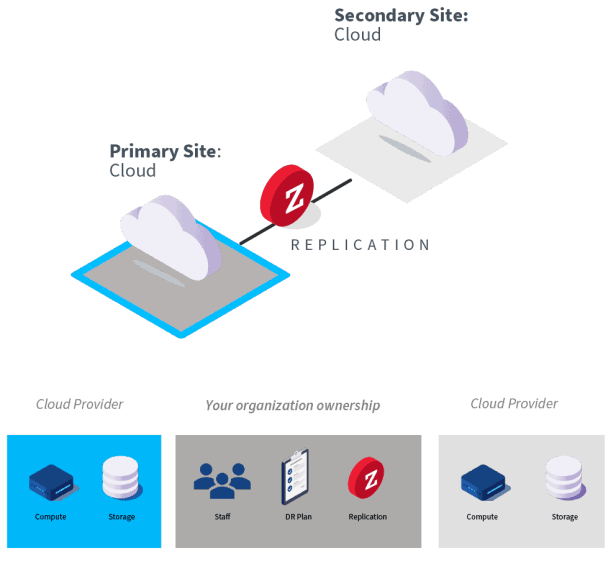
How it works
Here your primary site and resources are already in the cloud, and you use the same cloud or another one as your disaster recovery site. Using the same cloud provider for DR means that you will have to pay attention to how you can replicate between that cloud provider’s regions or zones to protect against a cloud outage. If you use a DR solution that enables you to replicate to other clouds, then most of the DR to cloud considerations would apply.
Many organizations that have moved their primary computing to the cloud are born in the cloud do not necessarily recognize the need for in-cloud DR. Larger cloud providers tend to be resilient with many datacenters supporting regions to keep data and services online making them more resilient than typical on-premises computing deployments. Still, even the largest cloud providers have outages and there are other disaster scenarios such as malware attacks and accidental configuration issues that may take your systems offline and require a DR solution to bring systems back online quickly. In-cloud DR is just as important as on-premises DR.
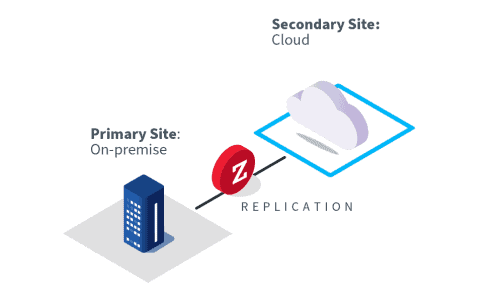
DRaaS
Disaster recovery as a service, or DRaaS, refers to contracting with a third party service provider to implement and manage your DR solution.
How it works
DRaaS is an excellent DR solution when your organization lacks in-house expertise or personnel to manage DR. Having an SLA with a managed DRaaS provider ensures that your RTO and RPO will always be maintained. Also, many of the compliance requirements relating to data and privacy may fall into the responsibility of the DRaaS provider within the DR solution and infrastructure.
The cost and TCO of DRaaS, will depend on the type of service selected. There are three main types of DRaaS:
- Self-service DRaaS means your organization carries responsibility for initial setup and for ongoing maintenance and monitoring while the provider provides the infrastructure and tooling.
- Assisted or Partially Managed DRaaS is where the management of the solution is shared between you and the service provider.
- Fully Managed DRaaS implied that the service provider will manage the entire DR solution.
The cost of DRaaS is similar to cloud in that there are predictable OPEX costs. The DRaaS provider is typically using cloud or their own managed infrastructure for the DR site. It is important to understand your critical IT assets and DR needs before choosing your DRaaS provider to ensure you are getting the right level of service you need and not overpaying for systems that do not need DR, or are not under-protecting your most critical systems.
The primary downside of DRaaS is that you are reliant on a third party should a disaster occur rather than being able to respond to the disaster on your own. It is crucial you understand how and if a DRaaS provider could sustain a major disaster or disruption in a given region as many of its customers would all try to recover at the same time, stressing the provider’s infrastructure, and overwhelming any connection bandwidth.
To Conclude
Disaster recovery is about supporting the ability of the business to recover quickly and continue operating after a disaster occurs. The threat of disasters impacting your business is very real and being unprepared is not an option. By taking steps to identify and measure the impact of your business-critical applications and systems and working to define the impact of data loss and downtime on your overall revenue, you can develop a cost-effective plan and choose the right DR solution to reduce the cost of downtime and improve your business resiliency in the face of any type of disaster.
Zerto has been a leader in DR for over a decade by providing the best RTOs and RPOs at scale for enterprise environments. Zerto brings together disaster recovery, ransomware resilience and multi-cloud mobility into a simple and scalable solution. Download the "Key Considerations for a Disaster Recovery Strategy" guide and see how Zerto can help you deliver effective IT disaster recovery.
MORE RESOURCES ABOUT DISASTER RECOVERY SEE ALL
Disaster Recovery You Can Trust
Learn how Zerto brings confidence in your disaster recovery planning and execution.
Demo: Disaster Recovery Use Case
Through a quick demo video, see a DR use case easily managed with Zerto.
What is Zerto?
Learn about Zerto and how it can help you solve your data protection and recovery challenges.