
DR 101: Calculating the Total Cost of Ownership (TCO) of Storage Based Replication
By Joshua Stenhouse, Zerto Technical Evangelist
When calculating the Total Cost of Ownership (TCO) of traditional storage based replication, for the protection of virtualized environments, there are many considerations that are often overlooked when comparing this to hypervisor-based replication. In this post I will cover some of the main things to look out for and explain how you can reduce the TCO.
1. Snapshot Space Utilization & Cost
Problem
Snapshots are typically used for either replication and/or point in time recovery of the data in storage based replication. Across most storage vendors the snapshots typically consume more than 20% of both the source and target storage, plus an additional 5% of replication reserve space. The cost and overheads of utilizing storage based replication must therefore include the cost per GB/TB multiplied by the storage usage of the snapshots and replication reservations.
As a simple hypothetical example take 2 x 200TB arrays, with 100TB of VM data replicated from source to target. Using storage based replication, 25% of data is lost to configuring the snapshots and replication, equaling 25TB of data in source, and another 25TB in the target storage array. This equals a total of 50TB of data out of 400TB across both arrays. If the cost of both arrays is $800k, 2k per TB, then the storage replication cost is $100,000. For this reason many storage vendors include the replication license in the cost of the storage, as it consumes more storage, meaning you need more disk space and/or a larger array.
Solution
By replicating from the hypervisor with journaling technology, rather than at the storage layer, there is no need to utilize snapshots for replication or point in time recovery. The ability to recover to previous points in time is enabled by keeping a journal on the recovery site storage, which dynamically grows and shrinks to the size of the changes in time it is configured to keep.
This results in the journal typically consuming 7-10% of the protected data set with absolutely no storage overheads on the production storage, while delivering a granularity of recovery in seconds rather than hours with snapshot based recovery.
Taking the same example of 400TB of storage with 100TB of VM data to protect, journal based protection would only consume 10TB of data in the recovery site. At $2k per TB the total storage cost would be $20,000, versus the $100,000 cost of storage replication, equaling a saving of $80,000 plus the benefits of increased granularity of recovery to minimize the impact of data loss.
2. Orchestration and Automation of Replicated Data
Problem
Utilizing storage replication simply creates a copy of the data in the recovery site. In order to use the data for disaster recovery and testing the recovery, it needs to either be recovered manually using scripts, or by utilizing an orchestration and automation solution.
Due to the time it takes to recover manually, the difficulty in testing and the lack of robustness in scripting, utilizing an additional orchestration and automation solution is often the most desired addition to storage replication. The cost of purchasing the licensing of the additional solution and managing multiple solutions should therefore be factored into the cost of storage replication.
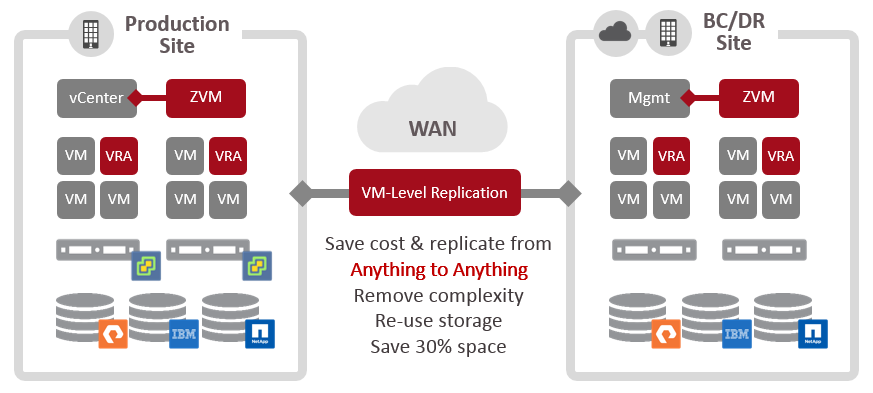
Solution
Rather than using one solution for data replication and another for orchestration and automation, you can reduce complexity by using one software solution for both. The same budgeted cost to buy a dedicated orchestration and automation solution can be re-purposed to buy a solution that does both functions from the hypervisor. You also gain the added benefit of reducing management overhead and saving on storage space, by not using snapshots for replication.
3. Storage Lock-In
Problem
By replicating at the storage layer, both the source and target storage array vendors, and models, have to match or be compatible. This can significantly increase the TCO of your next storage refresh by having to buy new, and matching, storage arrays just to configure replication.
There is no ability to mix and match storage vendors and technologies to get the best price to performance ratio in a recovery site, or to introduce new storage vendors to improve performance. The ability to even negotiate is also reduced, and existing storage cannot often be utilized with new storage reduced to reduce the cost of the storage refresh.
Solution
The lock-in of storage replication can be removed by replicating from the hypervisor, which allows replication from any storage to any storage. This allows you to buy or use any storage in a recovery site to reduce the cost of your next storage refresh. Even if the same storage is used in both source and target, replicating from the hypervisor removes complexity to save on the cost of management overheads. All of these capabilities combined can be used to reduce the TCO of your storage.
These are just some of the considerations that need consideration when comparing the TCO of traditional storage based replication with the TCO hypervevsior-based replication. In a future post I will analyze more, and if you have specific questions feel free to leave them in the comments below.
Become even more knowledgeable with our Disaster Recovery Essential Guide!


