
By Joshua Stenhouse, Technology Evangelist at Zerto
When using synchronous replication, a Recovery Point Objective (RPO) of zero only applies to disk writes and only if the disaster requires recovery to the most recent point in time. An RPO of zero on disk writes does not capture any transactions in-flight such as those in the memory of the application, hypervisor stack or in transit between the data-centers. Therefore, the only way to recover to the most recent or a previous guaranteed consistent point in time is to recover from a storage snapshot.
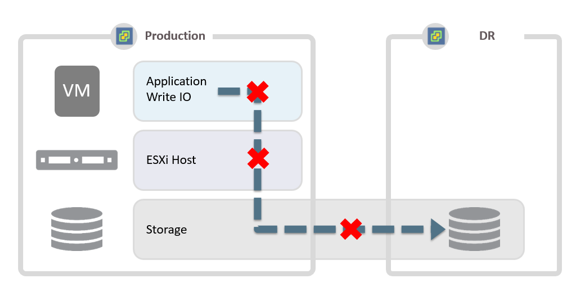
Storage snapshots are limited in frequency due to the stun overhead on VM performance, disk space usage and performance limitations of storage controllers. This results in a significantly higher RPO than 0 for a consistent recovery of VM data, often 15 minutes or above, and means that zero data loss is not achievable with synchronous replication technologies.
Zerto’s Virtual Replication (ZVR) completely removes the need to utilize snapshot technologies for consistent recovery while delivering a lower RPO than synchronous replication and storage snapshots. ZVR continuously tracks, streams and journals the VM block-level changes asynchronously from the hypervisor to maintain thousands of consistent points in time in the replica VM data. The replica data is updated continuously from just seconds behind production without ever impacting the performance of the VMs by never utilizing snapshots.
This enables the consistent recovery of the VMs to the most recent or a previous point in time on a granularity of seconds, unlike in-frequent snapshots which often contain the replicated error from which recovery is required, minimizing the RPO to just seconds when recovering from all types of disasters such as database corruptions and ransomware infections, not just a power outage.
Hypervisor vs storage replication IOs
When replicating at the storage level the data has to travel from the VM, through the VMware vSCSI bus, ESX storage driver, Host Bus Adapter, fabric and be processed storage controller before it is replicated. The more layers the IO has to pass through the more chance there are for errors or corruption of the IO. This increases the risk of bad data being replicated as the IO at the storage-layer is potentially not the same IO as originally created by the VM.
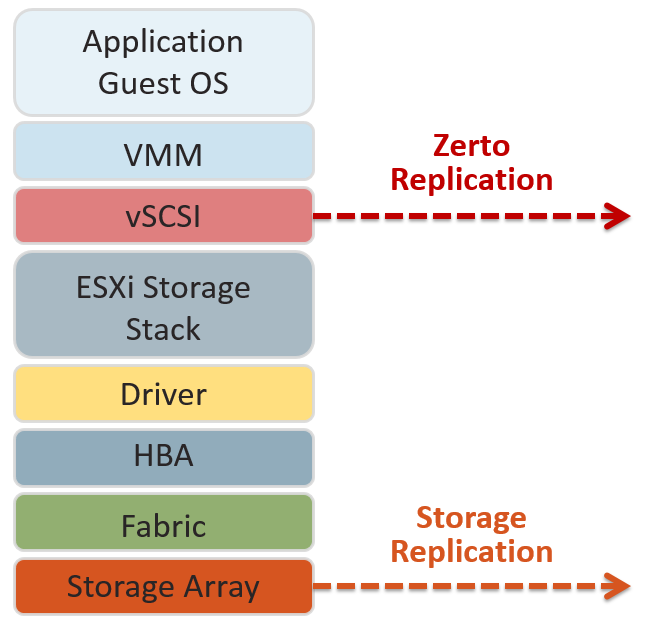
ZVR replicates the VM write IO from the vSCSI layer in the hypervisor using Virtual Replication Appliances (VRA) ensuring it is as close to the VM as possible to maintain consistency and integrity of the IO. The write is only replicated after it is acknowledged by the source storage array, to prevent replication of ghost writes, but it is replicating the IO of the VM, not the IO which the storage controller stored on disk.
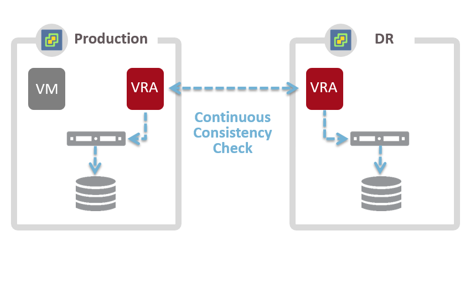
This fundamentally different replication creates a clean copy of the VM IOs, not the storage array IOs, making the replication process more efficient, reliable and removes the sole reliance on storage controllers to maintain consistency between source and replica data. ZVR further guarantees consistency by continuously checking the consistency of the source and replicated VM data using a passive parallel MD-5 hashing algorithm. This constantly runs in the background to maintain data integrity without impacting performance.
Latency & performance
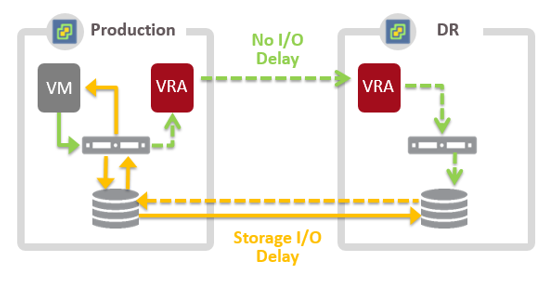
Synchronous storage replication technologies require the confirmation of a write in both datacenters before an acknowledgment is sent to the VM generating the IO. By leveraging dark fibre connectivity between datacenters the increase in latency from the round-trip of the write operation is minimized. Using legacy spinning disk based storage arrays and connectivity over a short enough distance, the performance of VMs can be sufficient in comparison to the performance of the storage over the link.
With new All Flash Arrays (AFAs) capable of 100,000s of IOPs with < 1ms average latency or hypervisor based storage using local flash caches, the performance bottleneck of a new datacenter is now legacy synchronous replication technologies over comparatively high latency links. Furthermore, this performance limitation is implemented with the belief that 0 data loss is achievable when it is not.
ZVR replicates VM writes asynchronously without having to wait for acknowledgement from the recovery site storage. This ensures there is no impact to the latency or throughput of a protected VM write allowing the use of new AFA or hypervisor-based storage with no degradation in VM performance. In turn this improves the performance and responsiveness of the VMs and applications that depend on the new storage performance while maximizing the return on investment.
LUN-based consistency groupings
In order to maintain consistency of multi-VM applications with storage snapshots all of the VMs need to be placed on the same LUN. This creates a significant management overhead and restrictions in a virtualized environment, reduces flexibility and wastes resources by replicating all of the data on the LUN, rather than just the VM data required a consistent recovery. Features such as VMware Storage vMotion cannot be utilized without re-replicating all of the protected VM data, removing the ability to use a key feature of VMware virtualization. Storage replication also requires matching vendors, models and LUN configurations between source and target datacenters creating complexity and lock-in.

ZVR removes the need to use LUN snapshots for consistency groupings by using Virtual Protection Groups (VPGs) in the hypervisor to enable replication from any storage to any storage. This enables the choice of replication between different storage vendors, models and LUN configurations by removing lock-in. By asynchronously inserting checkpoints across the replication I/O streams, validated in the target journal for consistency, ZVR enables a consistent recovery of the entire application stack to the exact same point in time across all of the disks and VMs in the application. This guarantees that all the VMs in the multi-VM application are recovered together from exactly the same point in time irrespective of the underlying LUN configuration.
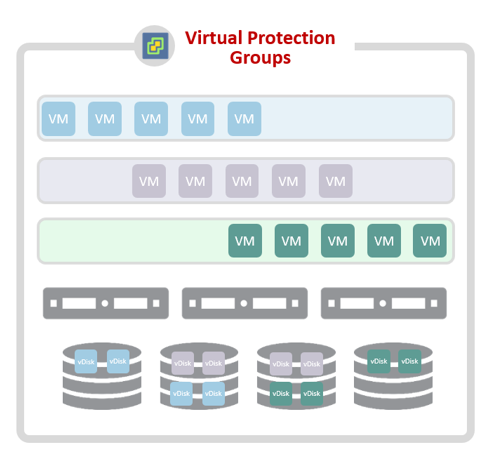
By utilizing VPGs the full benefits of virtualization can be realized. Storage vMotions can be leveraged with no impact to replication and no re-replication of data while only replicating the VMs required, not all the data on the LUN. This saves a significant amount of management and resource overhead as the protected VMs can be managed by the virtualization team without impact to the protection.
Recovery automation & testing
Synchronous storage replication creates copies of the data on the LUNs selected for replication in the target storage array. In order to recover the VMs 3 solutions can be utilized:
- Manual recovery
- Scripted recovery
- Orchestration & automation software
Many organizations choose manual or scripted recoveries due to the complexity and cost of buying and installing a solution to just handle the recovery and testing operations. This means that the majority of synchronous replication based environments have Recovery Time Objectives (RTOs) measured in hours to days, as the recovery needs to be performed manually or by using untested scripts. This also impacts disaster recovery testing frequency as downtime is required to complete the tests. In combination with staffing overheads this introduces a significant risk of the business not being able to recover from a disaster.
Some synchronous replication solutions are used as part a metro-cluster high availability solution. In this configuration all of the VMs are randomly restarted by a HA service in the alternate datacenter in the event of power loss. This scenario results in a potential RTO of many hours as the VMs are not recovered consistently or in the correct order. Manual operations are required by multiple database administrators and application owners to fix data consistency and service operations issues between application components to complete the recovery. There is also no ability to test the failover without performing a full simulation which creates downtime and impacts the business.
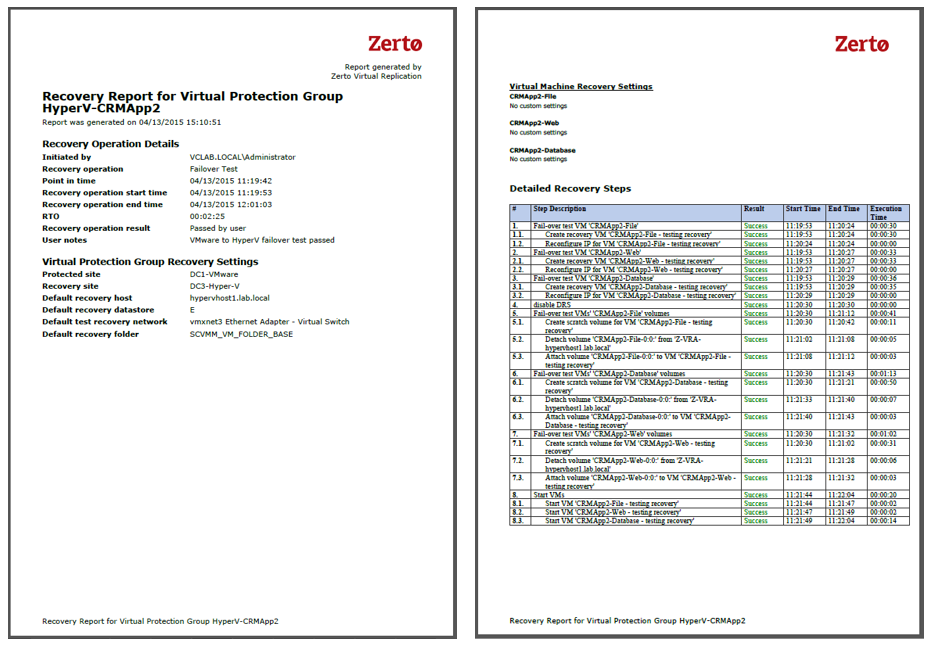
ZVR includes replication, recovery automation and orchestration all in one solution. The VMs that form each application are recovered together in a Virtual Protection Group from a consistent point in time. Boot ordering is then applied to ensure that the VMs come online in the correct order. This ensures an RTO of just minutes with no manual operations required as the application is recovered in a working and consistent state. No-impact failover testing also enables this automated process to be tested in working hours in minutes with no shutdown in production or break in replication. Reports can be generated from the testing outcomes to prove the recovery capability and in combination increase the frequency of DR testing, mitigate risk and remove business impact.
Become even more knowledgeable with our Disaster Recovery Essential Guide!


