How Does True Continuous Data Protection (CDP) Work?
Behind the Scenes of True CDP
One of my favorite parts about working at Zerto, a Hewlett Packard Enterprise company, is that often people don’t believe a word I’m saying. Whether that be on stage at an international event or in a small private meeting with customers and prospects, the comments I hear most often are:
“You can’t really do all of that.”
“This must just be marketing speak.”
My second favorite part is showing the world that, yes, we actually can do all of that. The full automation and orchestration of the Zerto solution is both simple and astounding. Zerto delivers recovery point objectives (RPO) of seconds across thousands of VMs and allows organizations to test disaster recovery (DR) and ransomware recovery in minutes without disruption and without impact to a production environment.
Once people are convinced that what we say we can do and that we can deliver upon our promises, their next question is:
“So, how does this work?”
My usual response is “magic.” However, in this blog, we will go behind the scenes to learn the story of the magic behind how the best CDP works. Here are some core principles that are crucial for the world’s best true CDP to provide an overall enterprise-grade level experience at scale.
Near-Synchronous Replication
The idea that continuous data protection (CDP) is just about getting I/O and data from one place to another quickly is a bit misplaced. Zerto has block-level replication that is near-synchronous, which takes the best properties of synchronous and asynchronous replication to provide customers with the best data replication experience. We take the speed of synchronous without the performance impact and take the efficiency and restore capabilities from asynchronous to combine into a unique near-synchronous replication engine. Not only does our near-synchronous replication engine work across all hardware and storage vendors, but it can also be used in the public cloud.
The near-synchronous replication engine works completely different from legacy or traditional data protection measures. There are no agents, no snapshots, and no schedules to maintain—replication is always on! How can this happen? Let me explain.
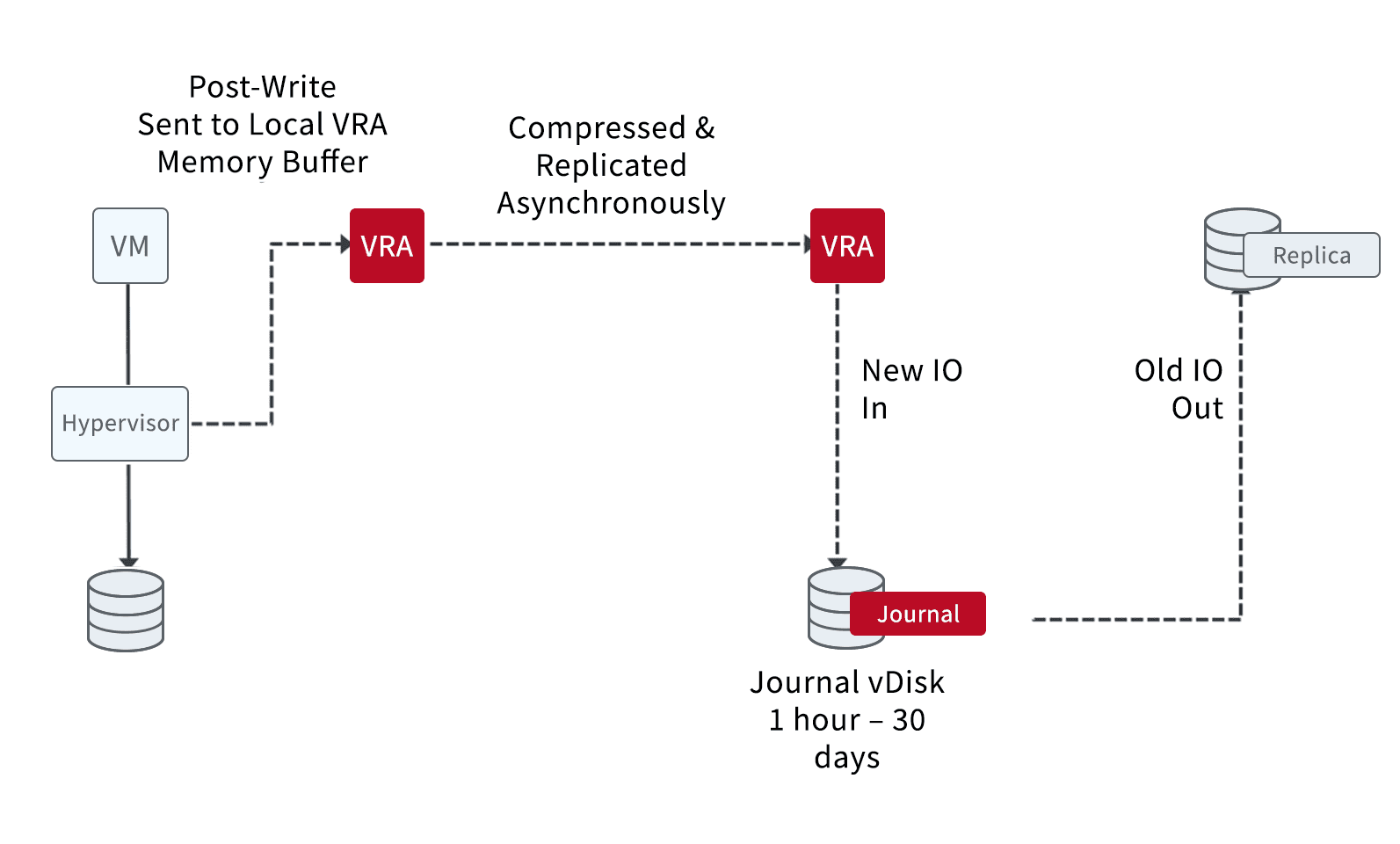
Capturing the IO
Zerto takes copies of the data as your virtual machine sends data via the hypervisor. We copy only the changed blocks in flight while in memory. This allows Zerto to have zero impact on production workloads and production storage arrays since we are not waiting for the I/O to hit the storage before reading it again.
Sending the Data
Once we have the data inside our data path, Zerto sees the acknowledgment back from the storage array, then compresses the data and sends it to your target site or sites. (Zerto can use CDP to replicate to multiple targets simultaneously.) When data is in flight, we insert checkpoints into it, which act as your recovery points.
Storing the Data
Once Zerto receives the data, we store it compressed in our unique journal. Retention times can be from one hour up to 30 days, the longest retention times on the market today. We can now use the recovery points we inserted in flight to recover the data with seconds of granularity and thousands of restore points.
Another Part of the CDP Story: The Zerto Journal
Now let’s dig deeper into our journal, another key part of the true continuous data protection story. The Zerto journal is where all replicated data is stored. Our journal is hyper-efficient in storing and using data, meaning we store only the minimal amount of data needed to recover. The Zerto journal offers huge granularity in restore points available but also allows us to recover a vast range of objects directly from the journal: whole sites, individual applications, single virtual machines, and even all the way down to a single file; and remember, this is all without agents!
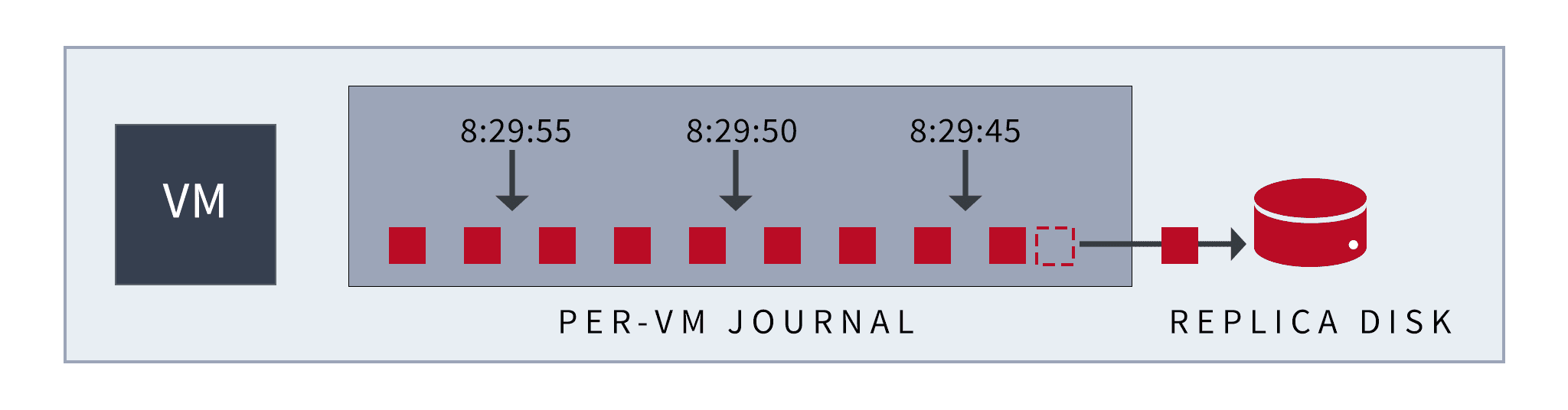
The journal simply allows us to recover the exact data we want from the exact point in time we want and recover it to the exact place we want. Isn’t that what everyone wants from their data protection software?
The Last Piece: Application-Centric Protection and Recovery
The last piece of the story is application-centric protection and recovery. Is that just a marketing term? At Zerto, no—it is a core concept to how we build and develop our software. Traditionally, data protection has ignored how the protected workloads are used. They break down large complex applications into their component parts, protect the data on an individual component basis, and put the task of rebuilding it all back together back upon the administrators. But not only does this give the admins a huge headache, but it also causes delays in recovery and increases the likelihood of human error.
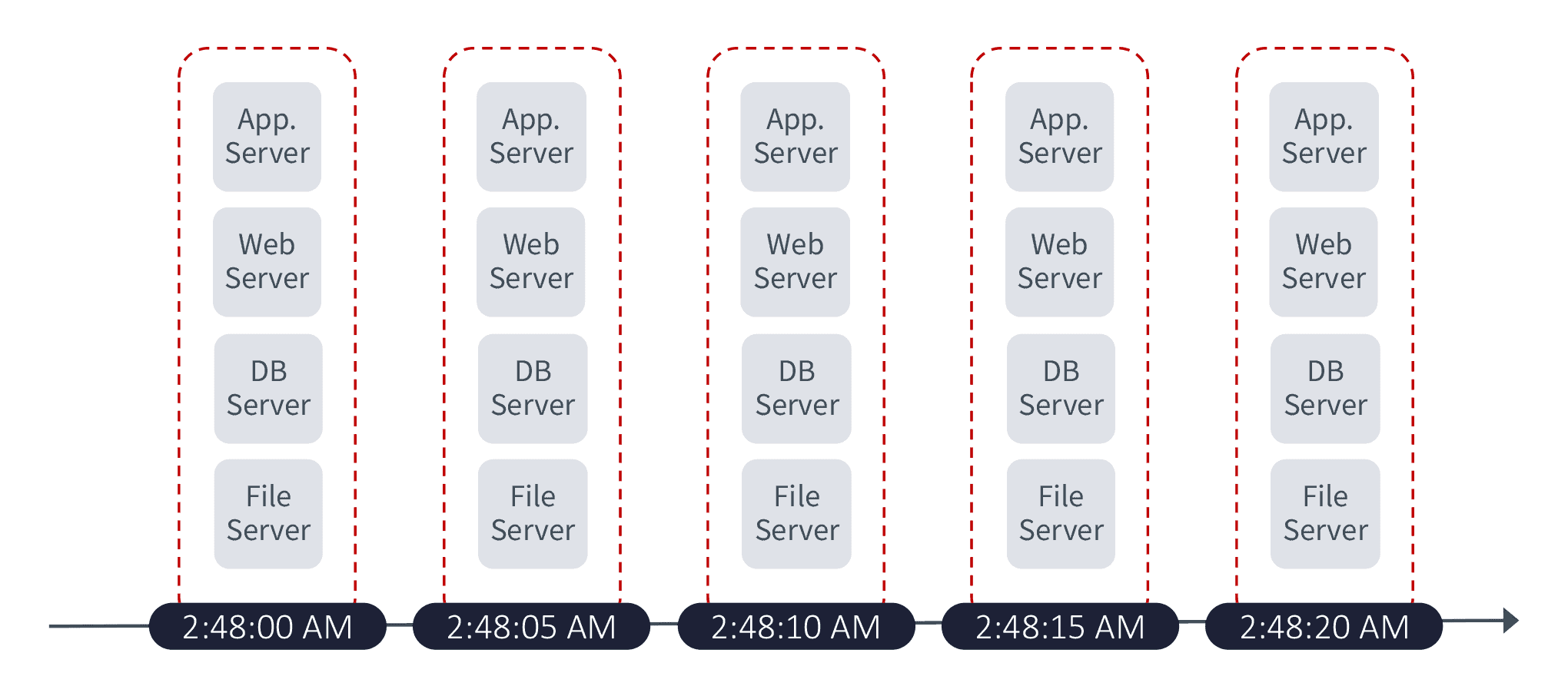
Application-centric protection and recovery at Zerto allows the applications to be protected and recovered as a single cohesive unit. Not only does Zerto make sure all components are recovered together, it also ensures each component part of the application is from the exact same point in time with write-order fidelity that is guaranteed across applications spanning multiple VMs, datastores, and hosts.
See for Yourself
“The proof is in the pudding,” as they say. The best way to discover the unique capabilities of Zerto is to try it for yourself. There are multiple ways of doing this:
- Hands-on Labs—Deploy a hands-on lab, free of charge, no infrastructure required, with fully guided labs to help you learn and understand Zerto. We even have Public Cloud and Recovering from Ransomware labs.
- Zerto Free Trial—Get complete access to Zerto for 14 days, right now, on your own hardware, in your own environment.
- Guided POC–If you have more bespoke requirements or a complex infrastructure in which you would like to install Zerto, we can link you up with one of our engineers who can help guide you through a proof-of-concept installation. Contact us.
Finally, if you want to learn even more about Zerto CDP, check out these resources.
 Chris Rogers
Chris Rogers