
ZVR 5.0 One-To-Many Use Case No.1 – Recover Directly to Production
Read an updated post, from 2023, on How Zerto’s One-to-Many Replication Works. Click here!
With Zerto Virtual Replication (ZVR) 5.0 One-To-Many replication, VMs can now be simultaneously protected both locally and to a remote site with always-on block-level replication, point in time recovery journaling and each replica just seconds behind the production data.
This enables fast, local, file and VM-level recovery from logical failures by enabling the recovery of the data from seconds before a corruption or deletion occurred. You no longer have to accept the data loss from trying to restore from infrequent and complex daily backups which struggle to complete given the increasing number of multi-TB VMs.
If you think about your 5TB SQL or Oracle database, 10TB Exchange mailbox server, 5TB file server, what if you could have a replica of those VMs continuously just seconds out of date, re-wind and recover the whole VM or any file from any point in time in the last 24 hours to 30-days directly to production? What if you didn’t have to try and squeeze your nightly backups into ever decreasing backup windows because the data is simply too big to backup? What if you could remove the performance impact of hourly or daily snapshots for backups? What if you could remove the complexity of trying to manage your backup scheduling, tracking and checking of nightly backup job completion?
With One-To-Many you can completely remove the whole notion of trying to perform nightly backups for short term data restores all with a granularity NO backup solution can ever achieve. Period. This leaves snapshot-based backups to what they do best, running once a week or once a month to create a portable and space efficient VM backup for long term retention and archiving purposes.
You can configure different 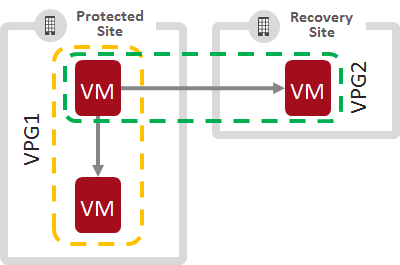 retention policies for both the local and remote replicas, anywhere from 1 hour to 30-days. Each replica uses journals with built-in compression of the block-level changes to maximize space efficiency and recovery granularity. Each journal contains checkpoints every few seconds and minutes to enable any point in time recovery. As a rule of thumb, we usually recommend 7-10% space overhead. I.E if you are protecting 100TB of VMs you would have a full copy of the VMs, to ensure maximum performance in a recovery scenario, plus 7-10TB for the compressed changed blocks.
retention policies for both the local and remote replicas, anywhere from 1 hour to 30-days. Each replica uses journals with built-in compression of the block-level changes to maximize space efficiency and recovery granularity. Each journal contains checkpoints every few seconds and minutes to enable any point in time recovery. As a rule of thumb, we usually recommend 7-10% space overhead. I.E if you are protecting 100TB of VMs you would have a full copy of the VMs, to ensure maximum performance in a recovery scenario, plus 7-10TB for the compressed changed blocks.
Wondering where you will get this storage from? If you have disk space currently used for short term backups, simply mount it on an ESXi host using VMFS or NFS and you can now perform local continuous replication to it from ZVR 5.0. Even if you are using a Windows server for disk storage you can easily use windows service for NFS to make it usable by the ESXi hosts.
This all sounds great, but your next question might be “what can I restore using Zerto One-To-Many replication? My xxxxxx snapshot-based backup solution can do 1 million things from the last performance crushing snapshot I managed get away with on my multi-TB production VM”. The simple answer is ANYTHING. How? Zerto gives you the ability to perform file level restores directly from the journal using the Zerto interface and isolated failover testing gives you the entire VM, database and application from the exact point in time needed to recover the data in minutes. Here are some examples:
- Need a file or folder from a file server? Simply select File Restore in the Zerto Virtual Manager (ZVM), select the point in time, the disk is mounted on the ZVM enabling files and folders to be downloaded in your browser and restored to wherever needed.
- Need a SQL or Oracle database from 4 hours ago on a VM containing 10 different databases? Easy, perform a failover test selecting the point in time required to an isolated bubble network, backup and export the SQL database.
- Need an Exchange mailbox item from yesterday at 2pm? Perform a failover test to the required point in time, the exchange server boots in the isolated bubble network in minutes, create and export a PST of the data needed.
In each of these scenarios the data can be restored from seconds before the data was corrupted or deleted without having to accept the data loss of going to the last backup. In comparison, backup solutions simply don’t have the data at the time you need it from! You might now be thinking “how do I export the data from a VM on an isolated network?”. Easy! It’s a VM connected to a port group that you create in your vSphere/Hyper-V environment and define on the VPG, you can therefore export the data many ways:
Option 1: Use a Data Transport VM with 1 NIC in the Isolated Bubble Restore network, that the failover test VM is connected to, and another NIC connected to the production network to restore the data directly to where it’s needed.
Option 2: Attach a RDM to the failover test VM, export the data to the disk, attach the RDM to the production VM using in-guest iSCSI (so it isn’t replicated by Zerto), restore the data directly to production.
Option 3: Use PowerCLI Copy-VMGuestFile to extract the file using VMware Tools: https://www.vmware.com/support/developer/PowerCLI/PowerCLI41/html/Copy-VMGuestFile.html
Option4: Attach a VMDK from NFS storage to the failover test VM, export the data, mount the VMDK on your Windows OS using OSFMount: http://www.osforensics.com/tools/mount-disk-images.html
Any which way you need it you can restore any file, database or application object from any point in time using Zerto One-To-Many replication, file-level restores and no-impact failover testing. Excited? I am! Watch out for the next blog post on One-To-Many replication where I will cover simultaneous on-premise and public cloud replication with RPOs in seconds and no performance impact.
Joshua Stenhouse
Technology Evangelist
Zerto


