
ZVR 5.0 One-To-Many Use Case No.4 – Protect Interdependent Applications
Read an updated post, from 2023, on How Zerto’s One-to-Many Replication Works. Click here!
Many organizations rely on applications and databases continuously updating each other in order to facilitate processes across multiple business units and systems. To help explain let’s take a typical scenario of a user who logs into application X, creates a new customer record, generates an order to be processed, invoice to be issued, delivery to be scheduled, account to be updated and so on and so on.
How many different databases, VMs and files systems were just simultaneously updated by interlinked systems, stored procedures and automated workflows? Probably more than anybody realizes or even has documented. I could say the exact same thing when I used to manage the virtual infrastructure for a law firm in Manchester (England) that had over 50 different applications. Upwards of 5 different application stacks, databases, each with different technologies and file systems could be updated hundreds of times for managing the case of 1 customer, never mind the thousands of cases and customers managed on a daily basis.
If I was to have a site wide outage, what happens if each of my VMs and applications are replicated and restored from completely different time stamp? The answer is bad things, really bad. While I might have recovered the VMs, I have left an absolute mess for the application owners and DBAs to clean-up, if they ever can. This means you cannot guarantee your Recovery Time Objectives (RTOs) to the business as you don’t know how long the clean-up process is going to take to get everything in a clean, consistent and working state ready for the business to resume normal operations.
Given these interdependencies, and the risk of not having everything recovered to the same point in time, what I really needed wasn’t just a Virtual Protection Group on a per application basis to recover my multi-VM application from logical failures, I needed a VPG containing all of my interdependent applications!
This would then give me the consistent recovery of all the VMs across all the applications from the exact same point in time. Not only that, I can now recover everything from any point in time in just 4 clicks and control the boot ordering of all the application VMs with boot groups to ensure the applications boot in the correct order. Winner!
In the example to the right we can see how this would be configured: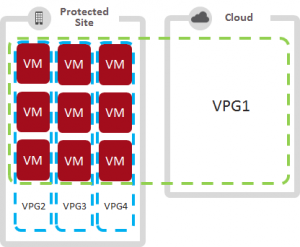
- VPG1 contains the 9 VMs that form 3 different interdependent applications replicating to the DR site for a consistent recovery of the entire stack
- VPG2,3,4 each contain the VMs for each multi-VM application replicating to the local datacenter for fast restores of individual applications in the event of a logical failure
At this point you might think that sounds awfully like a recovery plan and you’d be right, it essentially is. When paired with the ability to automatically change IP addresses, run custom scripts and perform no-impact failover testing you can guarantee the recovery of your entire data center in working hours in minutes with ZVR 5.0!
In my next blog post I will cover the brilliantly practical use case of One-To-Many replication for migrations to a new DR site which completely removes the risk of having no protection while migrating.
Joshua Stenhouse
Technical Evangelist
Zerto


