
Point in Time Recovery: Journal vs Snapshots
When evaluating different BC/DR solutions one important feature that users often look for is point in time recovery. The ability to recover to previous points in time is crucial in being able to recover from not only data center-wide issues, such as power loss or hardware failure, but logical failures, such as a database corruption, faulty upgrade, virus or user error.
When looking for this feature on the spec sheet of a particular BC/DR solution, there is a tendency to just check a box and say a replication engine either has it or it doesn’t, but this overlooks a huge potential pitfall. The biggest question any user should ask about point in time recovery is how is it achieved?
If it is done using snapshots on the replica VM, the technological choice of many free or SMB replication engines, then you may not be aware of the consequences of this. If you were to enable 24 points in time, and replicate 50 VMs, then you will be running on 24 x 50 snapshots in a recovery scenario. If you think the performance of a VM with 1 snapshot is bad then try running on 1,200!
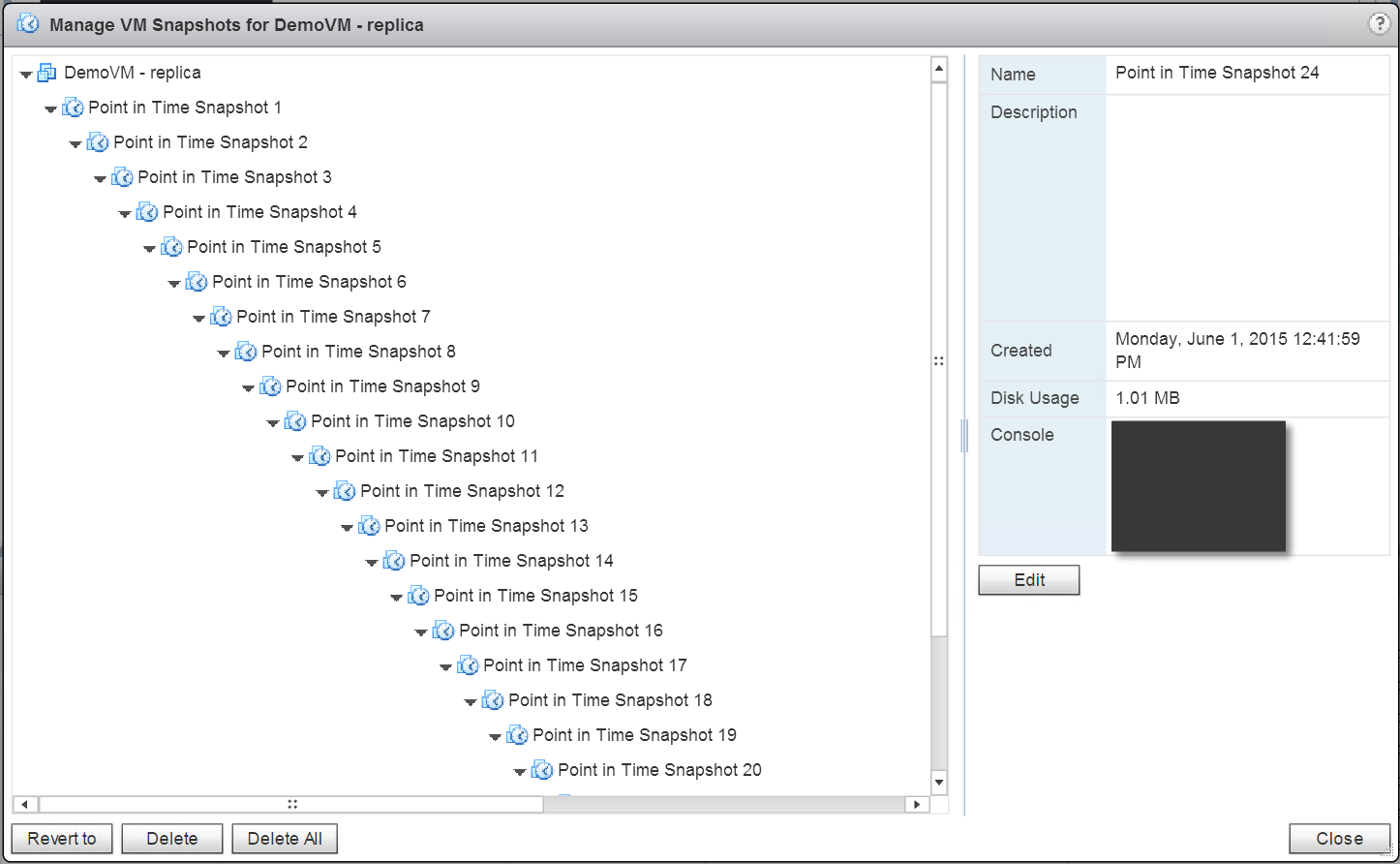
The impact is a severe performance degradation in a failover scenario that results in a Recovery Time Objective of many hours, if not days, to full performance. Attempting to consolidate so many snapshots after performing a recovery would also severely impact the performance of the storage which can potentially cause a 2nd disaster in itself, as the VMs grind to a halt. It gets worse:
- How do you manage the storage location of all the snapshots? You can’t as they are tied to the replica VM.
- How do you limit the maximum space usage of the snapshots? You can’t as they can grow indefinitely to fill the datastore.
- What happens if the last snapshot on the replica VM fills the datastore? It breaks the replica VM, requiring a re-sync.
- How do you recover to previous points in time consistently and in an automated manner? You can’t as each VM has to be rolled back manually and each VM is recovered to a completely different point in time potentially breaking the recovery of a multi-VM enterprise application.
- How do you reclaim wasted space after high data change rates? You can’t as snapshots are cascading and interdependent.
If you use a replication engine, such as Zerto’s Virtual Replication that uses journal based protection for point in time recovery, then all of these challenges are resolved as no snapshots are used on the replica VM. This is the fundamental reason why only journal based protection of VMs is scalable from 10s to hundreds or thousands of VMs, snapshot based replication should be limited to a handful of VMs from satellite offices at most. It also allows the following benefits to be realized:
- Recovery to increments every few seconds storing many days of change
- The ability to store the journal on a separate datastore
- Specify maximum size and warning limits
- Automated recovery of multiple VMs that form a single application to the same consistent previous point in time
- Reclamation of wasted space after periods of high data change
The next time you are evaluating a BC/DR solution I hope you find this useful in selecting a scalable enterprise-class BC/DR solution.


