
We all know and love virtual machines (VMs). You probably remember seeing your first vMotion or high availability (HA) failover event of a VM. How fantastic was it to free the operating system (OS) and application from the underlying hardware, optimize resource usage, and provide HA to any and all applications? VMs have served us well for the better part of two decades and we thank companies like VMware and Microsoft for that.
But containers are the new kid on the block and are becoming increasingly popular but differ significantly from virtual machines. Container technologies enable application developers to package small, focused code into independent, portable modules that include everything that’s needed to run the code—and, critically, only what’s needed to run the code, making building applications extremely agile. Let’s look at these differences between containers and virtual machines.
Main Differences between Containers and Virtual Machines (VMs)
Hypervisor vs. container host
The first big difference between the two is the way they run on hardware.
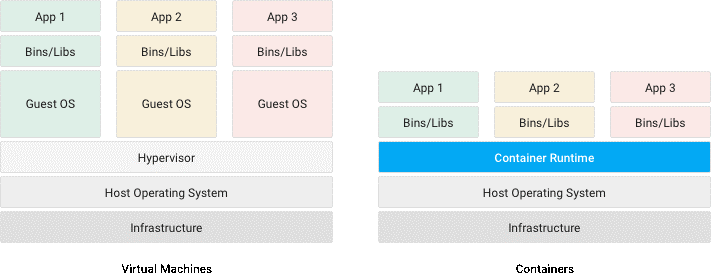
With virtualization, the hypervisor and physical processor create isolated resources for machines to run in. The hypervisor and processor then schedule resources for all VMs as effectively as they can. The hypervisor is in control of the hardware and allows the VM to run on the physical hardware directly. Resources, in this context, are the core four resources: compute, memory, storage, and networking.
Each VM has its own OS and a single physical server can run multiple OS distributions (e.g. Debian and Ubuntu) and even different kinds of operating systems (e.g. Linux and Windows). This allows maximum flexibility and compatibility but has some downsides in terms of resource optimization with multiple OSes running simultaneously.
Source: https://cloud.google.com/images/containers-landing/containers-101-2x.png
With containerization, the process isolation takes place inside the operating system’s kernel and isolates resources on a process level. Scheduling is no different than normal processes running in that kernel, but containerization adds a layer of isolation and security. Containers do not need to boot an entire OS while virtual machines do.
A single container host runs a single OS, and each container runs in that same kernel and operating system. Mixing containers with different OS kernels, such as Windows, Linux and MacOS, on a single container host is not possible.
So, the downsides are inter-OS flexibility and compatibility, but containers have obvious and significant advantages in resource usage. Containers can run anywhere: from a developer’s laptop, on-prem datacenters, and even in the public cloud. So, while inter-OS compatibility is lacking, the technology adoption is very widespread, negating much of the inter-OS compatibility issues.
Disk images
Disk images in virtual machines and containers are very different, too.
The first difference stems from the way they both run. A virtual machine disk image contains everything: the operating system, system packages, middleware like Java or .NET, the application, its configuration, and its data. VM images, even optimized templates, tend to run in the tens of gigabytes. And these disk images act like physical disks: just a bunch of block-based storage that the OS can see and write to. Again, the trade-off in benefits is maximum flexibility and compatibility, not performance, so the disks behave like physical disks without any bells and whistles.
Container images are much, much smaller. They consist of the bare minimum, usually just the application binaries and dependencies. There’s no operating system inside of the container image, nor any application data or application configuration. That makes them very lightweight compared to VM disk images.
Layers
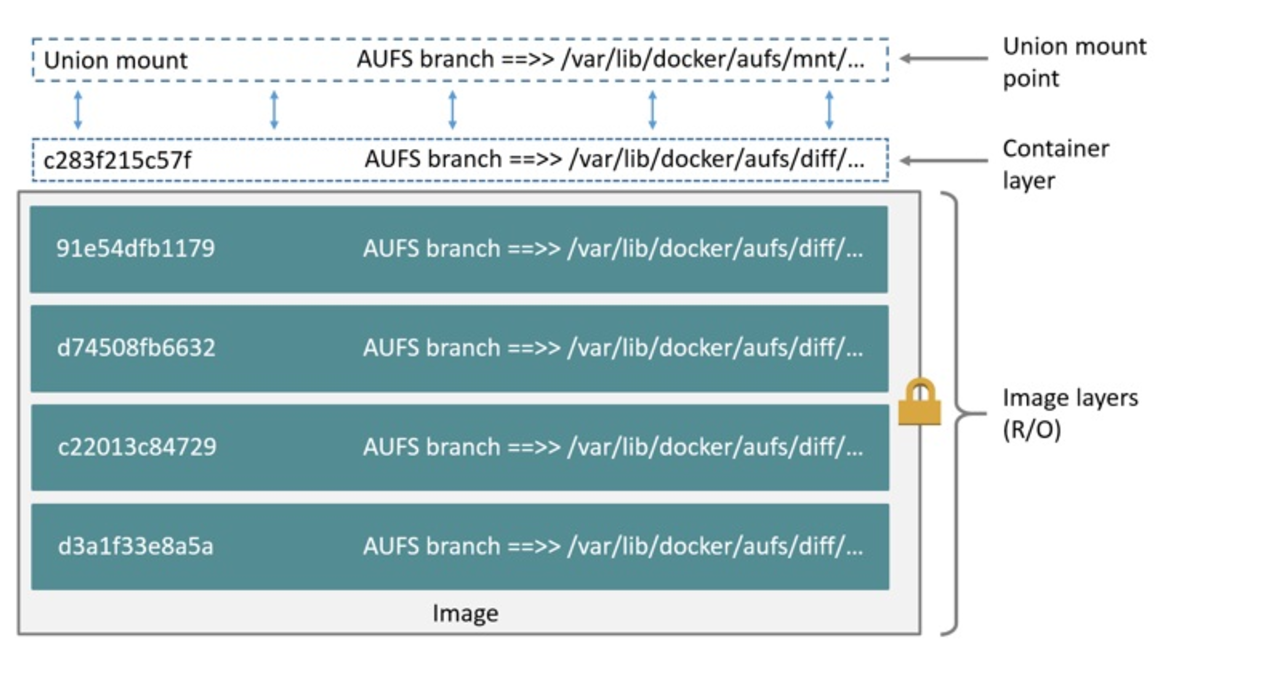
Although they’re lightweight and nimble, container images are a little more complex than a VM image for a wholly different reason. This is because container images are created as layers. A container image is a collection of many read-only layers with a single writable layer on top.
The intermediate read-only layers are built using commands in the configuration file (such as a Dockerfile). These commands install packages, include files, or set configuration items. That means the anatomy of each container is well-known, documented, traceable, and immutable.
Source: https://miro.medium.com/max/1400/1*st_fZmKOMykQGF8kZKglvA.png
The writable layer on top is unique to every running container, but it’s ephemeral. That means any changes to the container are stored only as long as the container exists. Start another container from the exact same container image and the changes do not carry over. If you stop and remove the container, the changes are lost.
Stateful vs. Stateless
That brings us to the last major difference between a container and a VM. Containers are stateless by design and applications don’t “store” data. And while wrapping your head around this fact is hard enough, it poses significant challenges for running stateful applications in a stateless container.
Unlike VMs, containerized application architecture needs to be much more explicit in where and how to store data:
- The application binaries usually are part of the container image and need to be included in the image build process.
- Application configuration will be different across different environments (development, test, acceptance, production) or regions (datacenters, cloud availability zones).
- And application data needs to be part of persistent data, which containers, luckily, can connect to via block, file, or object-based storage protocols.
We’ll expand more on stateful versus stateless in the next blog post.
Operational Differences
Architecture differences between VMs and containers also means the supporting ecosystem around the application and the containers needs to change with it. Monitoring, logging, security tools, and especially data protection need to be re-thought in order to support the container ecosystem.
From an operational perspective, that’s where the biggest difference is. The combination of the way they run, the stateless and layered disk image approach, and the significant impact they have on application architecture mean they’re very different operationally.
Containers require different operational tools, different processes, different know-how and experience, and a different approach. And with a fantastic, mature ecosystem of tools for VMs for monitoring, security, and data protection, containers may feel a little odd. It may feel like some pieces of the puzzle are missing—and they’re pieces that certainly are there in the virtualization ecosystem.
From an operational perspective, a lot of work needs be done to make sure containers can be first-class citizens without divesting the ecosystem of trusted and mature operational tooling and processes. And, importantly, without re-inventing the wheel: re-using existing solutions is preferred over investing money and time for training in a new set of tools.
Protect Your Containerized Applications with HPE GreenLake for Backup and Recovery
Containers open a world of agile development possibilities and should be explored as part of your IT strategy, and like VMs, containers are still susceptible to ransomware, that is why it is so important to ensure they are protected! HPE GreenLake for Backup and Recovery supports Amazon EKS, extending the way HPE enables cost-effective, long-term retention and helps customers protect against the business impact of unintended deletion, data loss through an infrastructure outage, or a ransomware attack.
To learn more, visit our HPE GreenLake Backup and Recovery page or watch this demo video to see it in action.


