
ZVR 5.0 One-To-Many Use Case No.3 – Recover Applications & Individual VMs Easily
Read an updated post, from 2023, on How Zerto’s One-to-Many Replication Works. Click here!
One of the key technologies of Zerto’s Virtual Replication (ZVR) is the Virtual Protection Group (VPG). The VPG mechanism is used for protecting and recovering application VMs together to a consistent point in time. Consistency is maintained across all the disks in a single VM or between all the disks and VMs in a multi-VM application. The technology was taken from LUN based replication where you could place all the VMs on the same LUN, snap it, then recover all the VMs from the same point in time for scalable recovery of enterprise multi-VM applications. The problem with this was that it was locked into the storage requiring complex LUN based replication, matching storage arrays, separate automation software and definitely had no ability to replicate to public clouds!
Zerto removed this lock-in and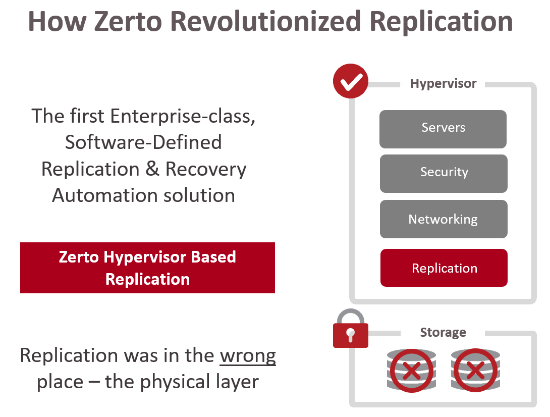 complexity by moving the replication into the hypervisor. When combined with VPG and journaling technologies this enabled the consistent recovery of multi-VM applications from any storage to any storage, from any point in time in the journal, and it’s the key differentiator against any VM-level replication solution that doesn’t have these technologies.
complexity by moving the replication into the hypervisor. When combined with VPG and journaling technologies this enabled the consistent recovery of multi-VM applications from any storage to any storage, from any point in time in the journal, and it’s the key differentiator against any VM-level replication solution that doesn’t have these technologies.
Without VPGs, the recovery of multi-VM applications can be a broken manual process as each VM in an application is replicated to a different time stamp. What happens if you recover your applications and the file server VMs contain don’t contain files referenced by your index VM? The database VM doesn’t contain any updates for the past 4 hours, yet all the other VMs are “in the future” in comparison to the database? These are scenarios you don’t want to be in after handing over the recovery operations to application owners and DBAs.
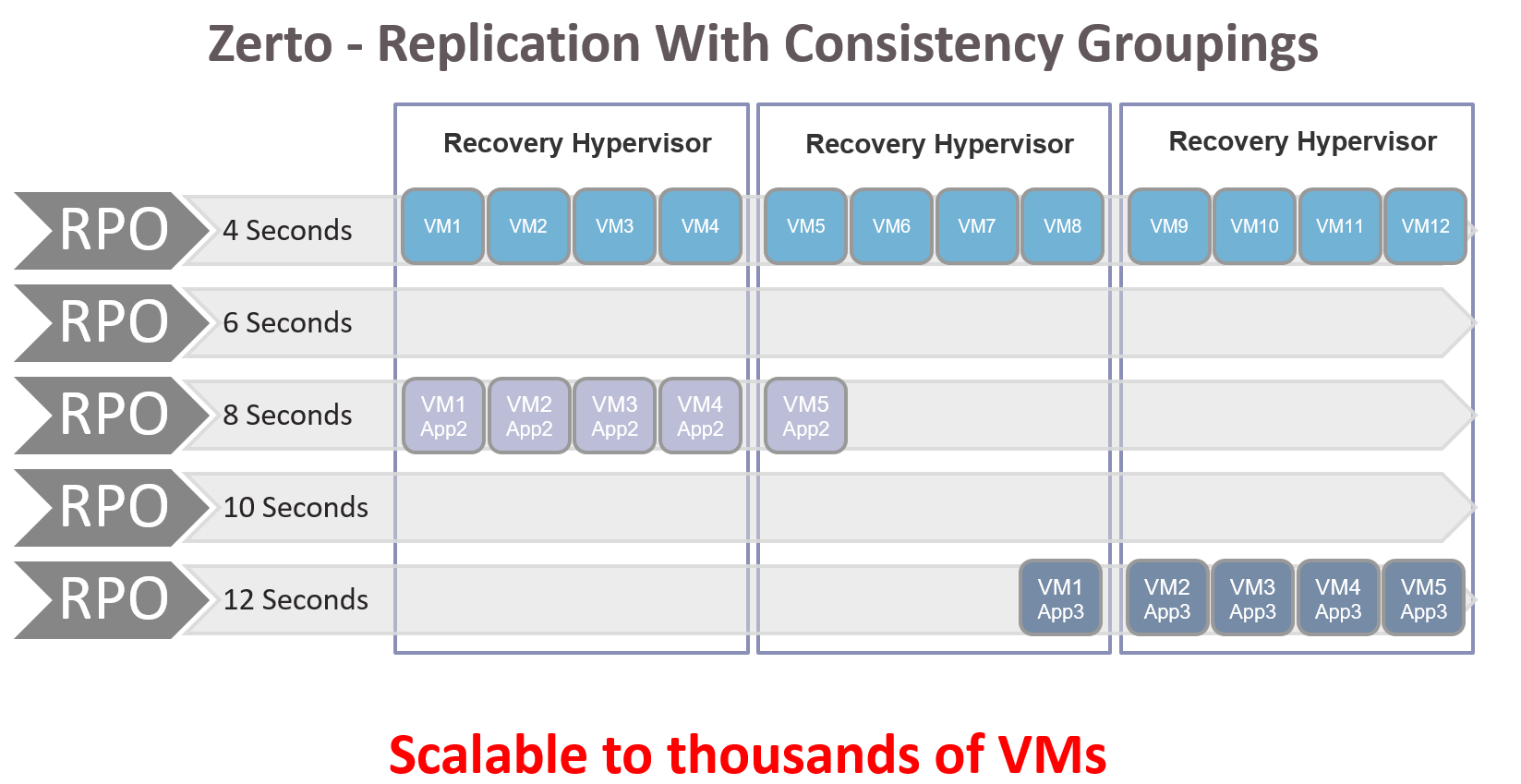

You might think this sounds like a no brainer at this point! I need this, and yes you do, but what if you just want to re-wind and recover a single VM to a previous point in time because of a logical failure within the application? You might not want to recover the VM to the DR site when all the other VMs in the app are in production as latency will break the app. You also don’t want to re-wind a database VM if the problem is only with a web server VM.
With One-To-Many replication we can literally kill 2 birds with 1 stone (sorry birds). How? Simply create local VPGs for individual VMs and remote VPGs for multi-VM application stacks to enable simple recovery of VMs directly to production or applications to a DR site.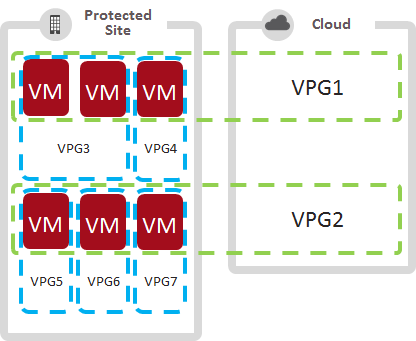
This gives you protection against logical failures without having to failover the VM to a DR site or manage a complex separate solution. Here we can see an example of this exact configuration:
- VPG1 and VPG2 are replicating 3 VMs, that each form their respective application stack, to the DR site enabling consistent recovery of the apps to any point in time
- VPG3,4,5,6,7 contain individual or smaller groups of VMs within the local datacenter enabling direct recovery of individual VMs to production from any point in time to protect against logical application failures
How cool is that? Restore any VM or application, consistently, from any point in time in your journal history to either production or your DR site! That is the power of ZVR 5.0 One-To-Many replication and one of my favorite use cases. In my next blog post I will take consistency groupings to the next level and cover the use case of using One-To-Many replication to recover both individual VMs, multi-VM applications and entire datacenters that contain multiple interdependent applications to the same point in time! Excited much? I am!
Joshua Stenhouse
Technical Evangelist
Zerto


