
Zerto vs vSphere Replication Comparison: How to Choose?
By Joshua Stenhouse, Zerto Senior Solutions Engineer
I’m blogging from the VMworld show floor this week, and one question that often comes up when discussing Zerto’s Virtual Replication (ZVR) is “How does ZVR compare against the built-in free vSphere Replication engine?”
Right off the bat, it should be noted that vSphere Replication on its own provides no central interface, no automation, recovery or testing workflows and requires VMWare Site Recovery Manager for this functionality.
This blog post will walk you through some specific examples of Zerto and vSphere Replication in order to show that Zerto’s Virtual Replication is a product relevant for enterprise replication and recovery and why we feel vSphere Replication is better suited to replicating a small numbers of VMs from branch offices.
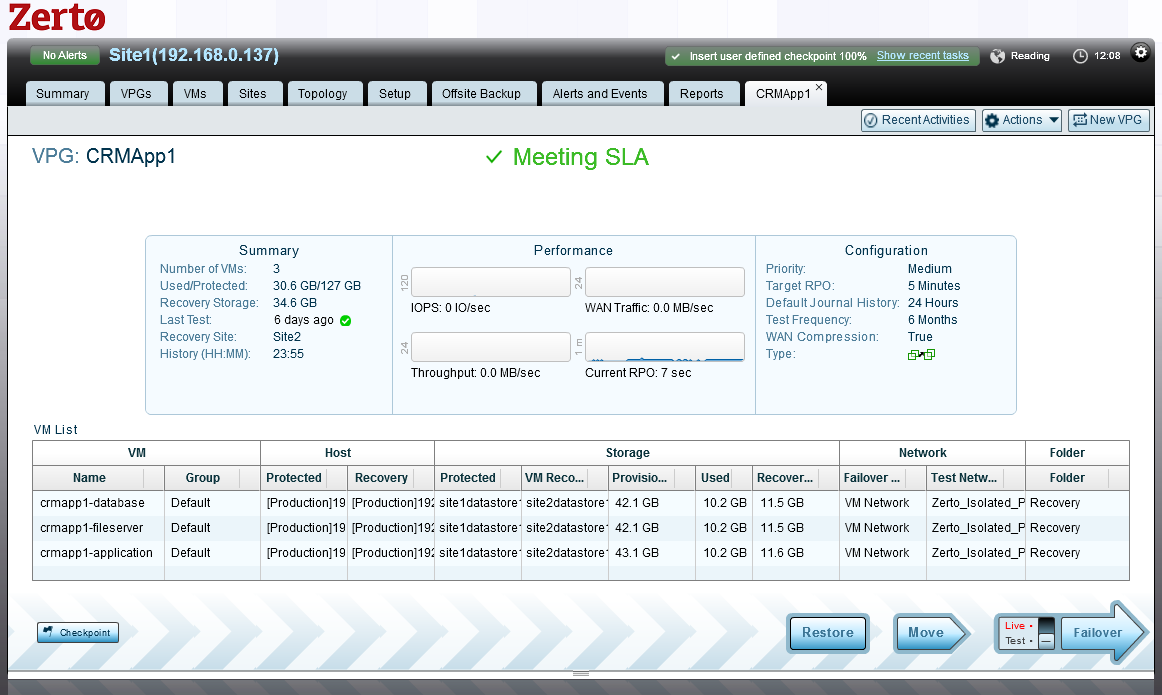
Zerto’s Virtual Replication provides continuous block level replication of changes giving a Recovery Point Objective of seconds, consistent across a multi-vm application, using Virtual Protection Group technology. With built-in bandwidth optimization and compression, Zerto’s Virtual Replication will automatically utilize the maximum assigned bandwidth and compress changes by 50%+ in order to maintain a consistently low Recovery Point Objective, that is consistent across a multi-VM application.
Here we can see all of the VMs in the CRMApp1 Virtual Protection Group are recoverable to 7 seconds ago from the Current RPO metric:
vSphere Replication doesn’t replicate continuously, nor does it replicate on a schedule like traditional replication technologies. vSphere replicates using a time slider which sets between 15 minutes and 24 hours. This controls how often it will attempt to replicate, subject to the data change rate (I.E completely randomly).
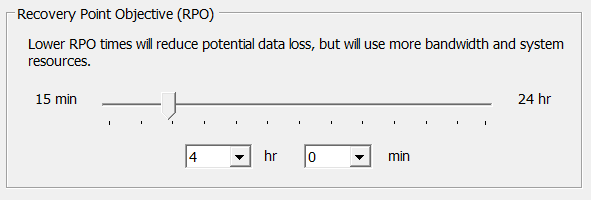
Be careful to ensure that this slider is of a sufficient gap to allow the data changing enough time to replicate, otherwise the replication will fail with an RPO violation. To attempt to work out how often the replication will occur, check out this official VMWare blog:
vSphere Replication has no consistency grouping of VMs and no bandwidth optimization and compression. This means vSphere Replication cannot replicate changes any faster, even if the bandwidth is available. Furthermore, it requires separate bandwidth compression appliances for compressing the replication traffic. Each replication interval will take a random amount of time, on a per VM basis, depending on the data change rate; meaning vSphere Replication will always run at random intervals with no way to control when it is or isn’t replicating.
So what does this fundamental difference mean in the real world?
I will demonstrate using a small environment consisting of 9 VMs that form 3 multi-VM applications; totaling 90GB of data replicating over a 1 Gbps link in my demo lab. Each application is a relatively basic CRM system with a database VM, fileserver VM and webserver VM that I need replicated to the same point in time. Without a consistent point in time, I could have a database referencing files that do not exist and a webserver containing logs pertaining to activities that are not in the database. Even with just this basic application you can appreciate this is not a good situation.
Using vSphere Replication if I protect the 9 VMs that form my 3 applications on a 1 hour RPO, and leave it running for 1 day, then what point in time am I able to failover my applications to?
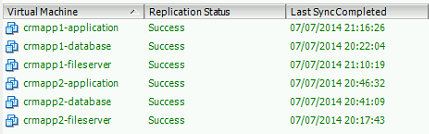
The answer is: I have no idea. vSphere Replication is giving me completely random point in time, on a per VM basis thus rendering the recovery of my enterprise application potentially useless. As a VMWare admin I would really want to avoid this for anything other than ROBO VMs (which Zerto Virtual Replication is also capable of protecting). In addition to this, I have no idea when vSphere Replication will attempt to replicate, and therefore I am certainly not going to enable VSS integration when I have no clue as to when it will attempt to quiesce my production applications!
This example is just from my demo lab running over a LAN, with no contention on the network link. What we have seen from customers trying to run vSphere replication in production over real WAN links is the lack of built-in compression makes the point in time difference between different VMs many hours, or just fails to complete at all, making the problem significantly worse.
If we take the exact same environment and protect it with Zerto’s Virtual Replication, leaving it for the same period of time, then what point in time can I failover to across my applications?
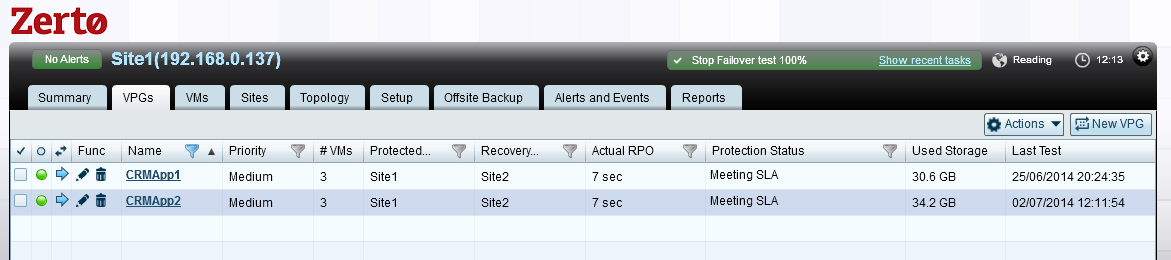
Looking at the Actual RPO column above, we see the answer is a few seconds ago to a consistent point in time across all of the VMs that form each application.
In this, the most basic of environments, which of the 2 replication engines do I want to rely on as a VMWare admin? From my 10 years of IT admin experience, it is an absolute no-brainer for Zerto’s Virtual Replication. I can also schedule when I take VSS points in time and I can failover to any point in time, every few seconds for crash consistency, up to 5 days in the past.
This fundamental difference is the main reason why Zerto’s Virtual Replication is scalable to thousands of VMs for enterprise data center-to-data center replication. vSphere Replication is a ROBO feature for a handful of VMs created in order for VMWare to check a box against an increasingly threatening Hyper-V feature set.
Don’t just take my word for it; feel free to validate my opinion and results by testing out Zerto’s Virtual Replication against vSphere Replication yourself with our free trial.
The points made above are also be worth considering when looking at using vCHS-DR against Zerto’s Virtual Replication to replicate to a cloud provider, considering that vCHS-DR runs using the vSphere Replication engine capability.


